Fast and Affordable LLMs serving on Intel Arc Pro B-Series GPUs with vLLM
Intel® Arc™ Pro B-Series GPU Family GPUs deliver powerful AI capabilities with a focus on accessibility and exceptional price-to-performance ratios. Their large memory capacity and scalability with multi-GPU setups make it possible to run the latest, large and capable AI models locally, making advanced AI inference accessible to professionals looking to deploy Large Language Models (LLMs) without the premium costs typically associated with AI hardware.
vLLM is at the core of the software stack enabling fast and cost-effective LLM serving on Intel Arc Pro B-Series GPUs. Over the past few months, Intel developers have been actively collaborating with the vLLM community to enable and optimize key features and ensure seamless performance with multi-GPU scaling and PCIe P2P data transfer on Intel Arc Pro B-Series GPUs.
vLLM is at the core of the software stack enabling fast and cost-effective LLM serving on Intel Arc Pro B-Series GPUs. Over the past few months, Intel developers have been actively collaborating with the vLLM community to enable and optimize key features and ensure seamless performance with multi-GPU scaling and PCIe P2P data transfer on Intel Arc Pro B-Series GPUs.
Based on vLLM v1 engine, Intel® Arc™ Pro B-series GPUs provide vLLM key features and optimizations including:
- Solid inference performance for DeepSeek distilled llama/qwen models
- Long context length (>50K) with good scaling on batch size
- Support for embedding, reranker, pooling models
- Support multi-modality models
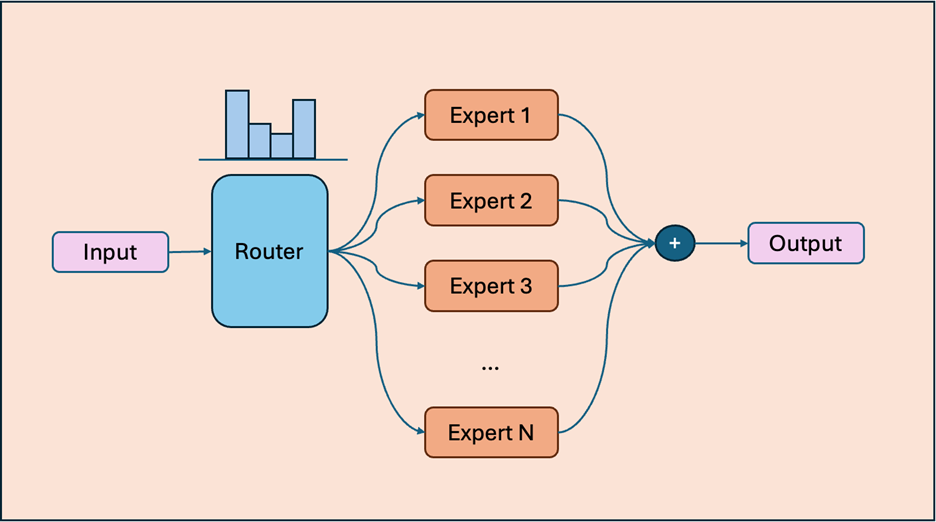
- Well optimized Mixture of Experts (MoE) models (GPT-OSS, DeepSeek-v2-lite, Qwen3-30B-A3B etc)
- By-layer online quantization to reduce the required GPU memory
- Support for Data Parallelism, Tensor Parallelism and Pipeline Parallelism
- FP16 and BF16 path support for Torch.compile
- Speculative decoding in methods n-gram, EAGLE and EAGLE3
- Async scheduling
- Prefill/Decode disaggregation
- Low-Rank Adapter (LoRA)
- Reasoning output
- Sleep mode
- Structured outputs
- Tool calling
- Mixed precision support for BF16, FP16, INT4 and FP8 vLLM recipes
Advanced Optimizations for MoE Models
Mixture of Experts (MoE) is a model approach where multiple specialized expert networks collaborate to process input sequences, guided by a gating mechanism. For each token in the input sequence, the gating network dynamically selects which subset of experts should process that token. Rather than relying on a single dense feedforward layer, MoE architectures employ multiple parallel GEMM operations distributed across expert networks to achieve equivalent computational functionality. This design introduces structured sparsity into the model, as only a subset of experts is activated for any given input, thereby improving computational efficiency while maintaining model capacity. Beyond general optimizations for General Matrix Multiplications (GEMM) and Flash Attention, these MoE components (experts and gating network) represent the key performance contributors in MoE-based language models.
However, naive implementations of MoE GEMM operations can suffer from significant efficiency bottlenecks. The typical approach, where individual GEMM kernels are sequentially launched per iteration on a for-loop, generates excessive kernel launch overhead and introduces substantial scheduling latency. Furthermore, since expert routing decisions are produced by the gating network, GEMM operations must wait for gate computation to complete before execution can begin. This data dependency creates pipeline stalls that disrupt the kernel execution stream and severely limit GPU parallelism, preventing optimal device utilization.
Targeting these limitations of MoE GEMM we designed a persistent zero gap kernel which achieved over 80% efficiency of hardware capacity of Intel® Arc™ Pro B60 GPU.
Optimization 1. Single kernel launched in persistent loop
Single kernel design will remove launching and scheduling overhead mentioned above. Also, persistent loop removes the need for launching parameters which depends on the results of expert routing network. They help keep maximum device parallelism.
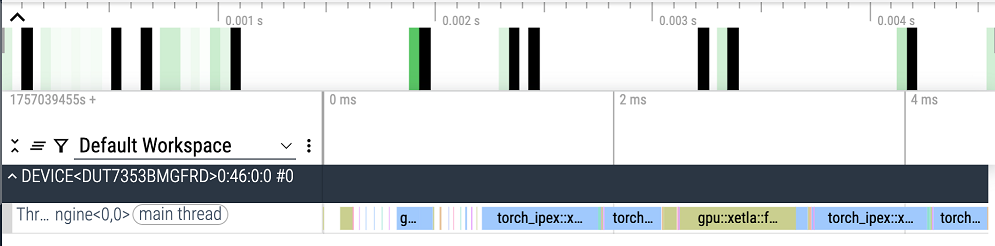
Before persistent kernel, we could see device idle for host waiting
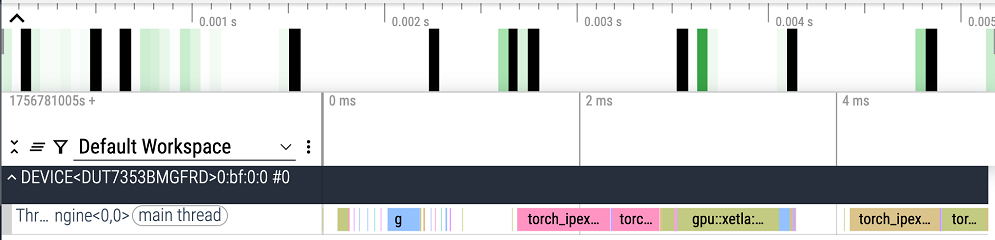
Enabling persistent keep device busy:
Intel® Arc™ Pro B60 GPU has 20 XeCores, each with identical resources that can host multiple SYCL groups. In our design, we launch two groups per XeCore to balance compute and memory bandwidth needs.
Optimization 2. Dynamic balancing of computing groups
One observation is that each group runs a different amount of work due to the imbalance of expert routing. If a group loops fixed stride of work, there is always a group that takes the largest amount of work and another, smallest. The gap between them will accumulate up to 15% of the total MoE GEMM time. A better alternative is whoever finishes a task in one loop starts the immediate available task in the next loop. For a concrete example, there are 40 groups to crunch 200 GEMM blocks, static stride will result that group 0 loop through 0, 40, 80, … group 1 loop through 1, 41, 81, etc. A caveat is that due to the nature of MoE, each GEMM block may not have same amount of compute intensity. Also, randomized access patterns will let certain groups finish work faster than others. This will limit efficiency in such a way that the groups always finished job earlier can’t help those always meet heavy loads.
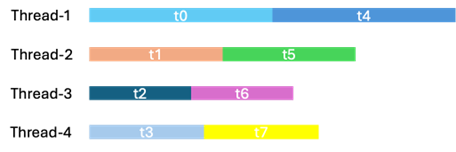

We mitigate the effect by letting each group compete for the next job through an atomic number. Whoever finishes computing one GEMM block will get a rank from the atomic number who decides which next block it’ll take. In this case, we eliminated small gaps in kernel looping and achieved perfect scheduling among all scenarios of experts routing.
Optimization 3. Fast MXFP4 to BFLOAT16 algorithm with prepack for memory load efficiency
Prepacking has long been known to improve memory load efficiency. For 4-bit memory loads, a hardware-friendly format can increase efficiency by up to 30%, as observed in our case. Also, naive FP4 to BF16 incurs too many instructions which prompt a need for better alternative (borrow from oneDNN, stride E2M1 encoding on single precision E/M position and multiple the scale difference between two types): Bitcast-bf16 ((x « 12) » 6 & 0x81c0) * 2^126 The solution minimizes instructions needed to convert fp4 to bf16.
Performance
With 24GB of high-bandwidth VRAM, 456 GB/s memory bandwidth and 160 Intel® Xe Matrix Extensions (Intel® XMX) AI engines, Intel Arc Pro B-Series GPUs offers good hardware capacity for the optimization of high touch models on vLLM . The full support model list can be found at intel/ai-containers
DeepSeek distilled models sized from 8B to 70B are optimized for good output token throughput on a system with eight Intel® Arc™ Pro GPUs.
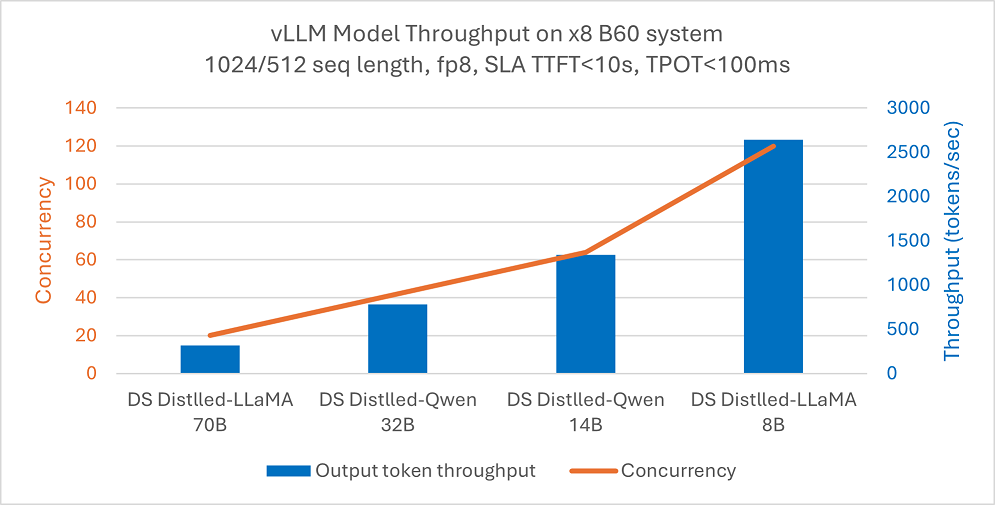
Figure 1: FP8 model output token throughput with max concurrency under SLA on a system configured with 8 Intel® Arc™ Pro B60 GPU cards
The system sustains less than 100 ms next token latencies with good concurrency load.
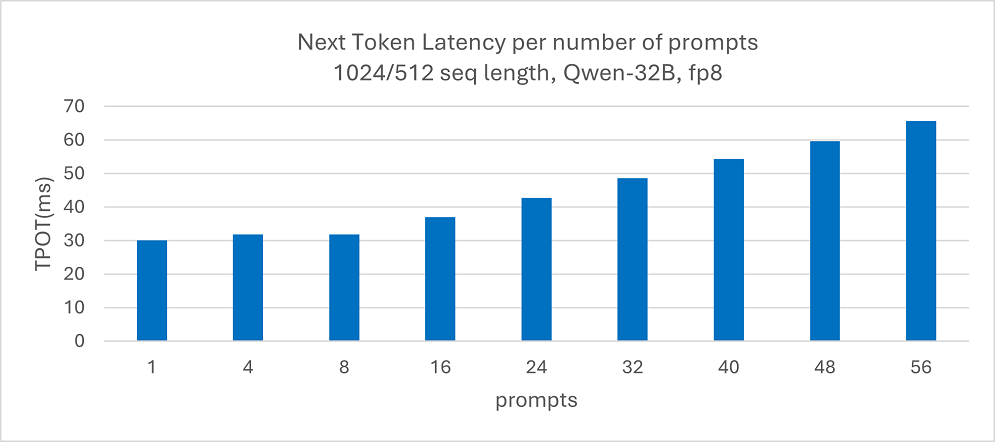
Figure 2: Qwen-32B next token latency with increasing number of prompts on a system configured with 4 Intel® Arc™ Pro B60 GPU cards
The model inference maintains consistent next-token latency across a wide range of input sequence lengths, scaling from 1K to over 40K tokens. This performance is underpinned by highly optimized flash attention kernels that parallelize operations across the sequence length dimension.
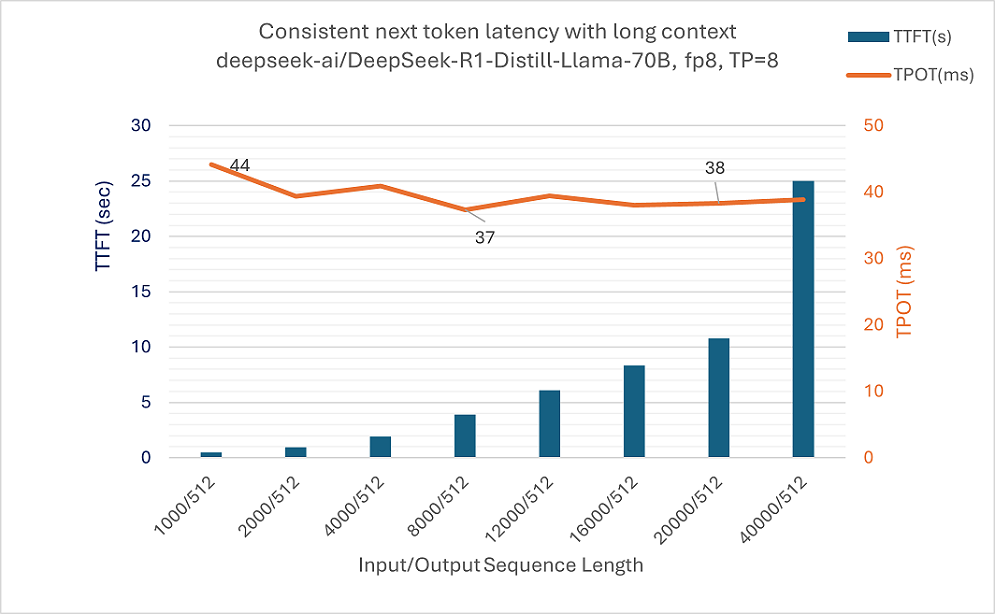
Figure 3: TTFT/TPOT for llama-70B single batch with long context input from 1K to 40K sequences on a system configured with 8 Intel® Arc™ Pro B60 GPU cards
GPT-OSS: Intel® Arc™ Pro B60 GPU also demonstrates exceptional performance with OpenAI’s recently launched GPT-OSS model, providing developers and enterprises with a powerful, cost-effective solution for large-scale AI inference as shown in the table below.
| Model | Data type | TP | Input/output seq length | Concurrency | TTFT (s) | TPOT (ms) | Output Token Throughput (toks/s) |
|---|---|---|---|---|---|---|---|
| GPT-OSS-20b | MXFP4 | 1 | 1024/1024 | 75 | 7.614 | 53.96 | 1210.74 |
| GPT-OSS-20b | MXFP4 | 1 | 2048/2048 | 38 | 7.823 | 42.35 | 818.92 |
| GPT-OSS-20b | MXFP4 | 1 | 5120/5120 | 15 | 8.36 | 34.27 | 416.94 |
| GPT-OSS-120b | MXFP4 | 4 | 1024/1024 | 100 | 8.04 | 58.78 | 1495.12 |
| GPT-OSS-120b | MXFP4 | 4 | 2048/2048 | 50 | 8.11 | 41.98 | 1085.58 |
| GPT-OSS-120b | MXFP4 | 4 | 5120/5120 | 20 | 8.60 | 30.60 | 619.10 |
Table 1: GPT-OSS vLLM inference throughput using 1-4 GPUs on x8 Intel® Arc™ Pro B-series System
MLPerf: Intel Arc Pro B-Series GPUs shines in the recently published MLPerf Inference v5.1 results (link). In Llama 8B, Intel® Arc™ Pro B60 GPU demonstrates performance-per-dollar advantages. The results were achieved with vLLM as the serving framework.
How to setup
The vllm docker image for Intel XPU support can be downloaded from intel/vllm - Docker Image | Docker Hub. The MoE models like gpt-oss is supported since vllm 0.10.2 docker release. Below examples require host OS: Ubuntu 25.04, KMD Driver: 6.14.0, running on the Xeon system configured with 4 Intel® Arc™ Pro B60 GPU cards plugged on PCIe slots.
# Get the released docker image with command
$ docker pull intel/vllm:0.10.2-xpu
# Instantiate a docker container with command
$ docker run -t -d --shm-size 10g --net=host --ipc=host --privileged -v /dev/dri/by-path:/dev/dri/by-path --name=vllm-test --device /dev/dri:/dev/dri --entrypoint= intel/vllm:0.10.2-xpu /bin/bash
# Run the vllm server with gpt-oss-120b on 4 Intel® Arc™ Pro B60 cards
$ vllm serve openai/gpt-oss-120b --dtype=bfloat16 --enforce-eager --port 8000 --host 0.0.0.0 --trust-remote-code --gpu-memory-util=0.9 --no-enable-prefix-caching --max-num-batched-tokens=8192 --disable-log-requests --max-model-len=16384 --block-size 64 -tp 4
# Start another shell and run the benchmarking
$ vllm bench serve --model --model openai/gpt-oss-120b --dataset-name sonnet --dataset-path="./benchmarks/sonnet.txt" --sonnet-input-len=1024 --sonnet-output-len=1024 --ignore-eos --num-prompt 1 --trust_remote_code --request-rate inf --backend vllm --port=8000 --host 0.0.0.0
More validated supported model list can be found here: Supported Models
Looking Ahead
We commit to deepening the integration between our optimizations and the core vLLM project. Our roadmap includes providing full support for upstream vLLM features, delivering state-of-the-art performance optimizations for a broad range of models, with a special focus on popular, high-performance LLMs on Intel® hardware, and actively contributing our enhancements back to the vLLM upstream community.
Acknowledgement
We would like to express our sincere appreciation to the entire vLLM team. Their groundbreaking work has set a new standard for LLM serving. The openness and support have enabled us to contribute effectively, and we are truly thankful for their partnership in this endeavor.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. Visit MLCommons for more details. No product or component can be absolutely secure. Intel technologies may require enabled hardware, software or service activation.